DiffusionSeeder
DiffusionSeeder: Seeding Motion Optimization with Diffusion for Rapid Motion Planning
TL;DR:We propose DiffusionSeeder, a diffusion based method that generates diverse, multi-modal trajectories to warm start motion optimization, greatly reducing the planning time on “hard problems”.
Overview
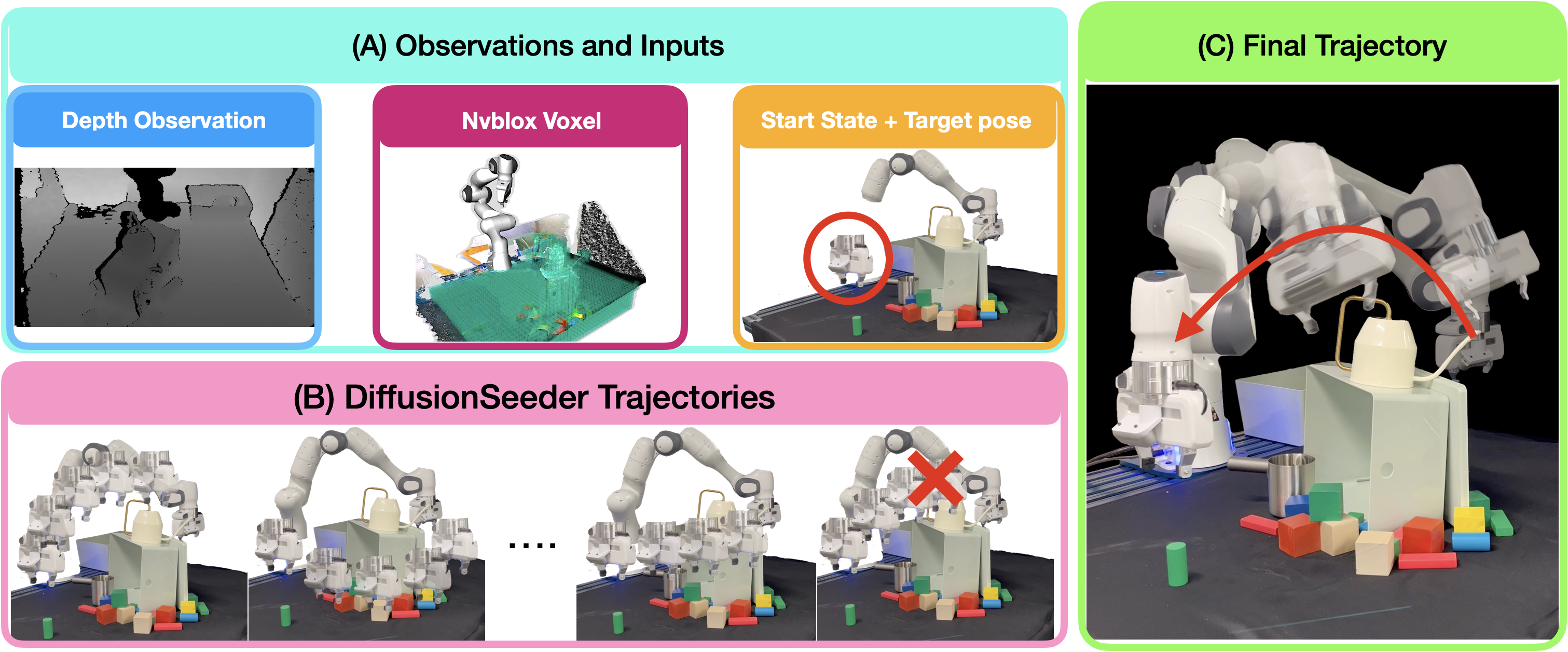
Running optimization across many parallel seeds leveraging GPU compute have relaxed the need for a good initialization, but this can fail if the problem is highly non-convex as all seeds could get stuck in local minima. One such setting is collision-free motion optimization for robot manipulation, where optimization converges quickly on easy problems but struggle in obstacle dense environments (e.g., a cluttered cabinet or table). In these situations, graph-based planning algorithms are used to obtain seeds, resulting in significant slowdowns. We propose DiffusionSeeder, a diffusion based approach that generates trajectories to seed motion optimization for rapid robot motion planning. DiffusionSeeder takes the initial depth image observation of the scene and generates high quality, multi-modal trajectories that are then fine-tuned with few iterations of motion optimization. We integrated DiffusionSeeder to generate the seed trajectories for cuRobo, a GPU-accelerated motion optimization method, which results in 12x speed up on average, and 36x speed up for more complicated problems, while achieving 10% higher success rate in partially observed simulation environments. Our results show the effectiveness of using diverse solutions from a learned diffusion model. Physical experiments on a Franka robot demonstrate the sim2real transfer of DiffusionSeeder to the real robot, with an average success rate of 86% and planning time of 26ms, improving on cuRobo by 51% higher success rate while also being 2.5x faster.
Methodology
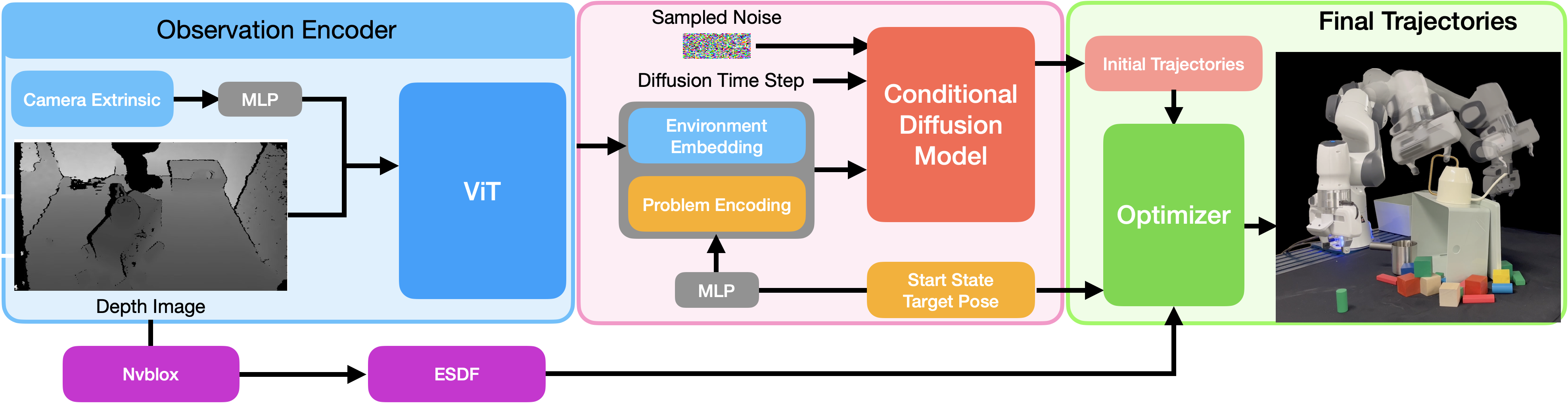
DiffusionSeeder trajectory generation pipeline. DiffusionSeeder consists of a ViT observation encoder (blue) and a conditional diffusion model (coral). The robot start configuration and target pose are embedded through an MLP into a “problem encoding”, which is concatenated with the environment embedding. The diffusion model conditions on the concatenated vector and a randomly-sampled noise tensor of size 32×7 to generate initial trajectories for the optimizer (green). The optimizer takes in the ESDF for collision checking. The final trajectory after optimization is shown on the right.
Model Architecture and Training
Observation Encoder The observation encoder processes depth images, camera poses, start joint configuration, and goal pose to create a single embedding vector as the condition of the denoising diffusion process. Specifically, we use a ViT with 12 layers and 12 heads as the network backbone. Depth images, projected to 3D using camera intrinsics, are divided into 64 × 64 patches where each patch is encoded first and concatenated with the linear projection of the SE(3) homogeneous transformation of each camera pose. We add a positional embedding to each patch embedding, resulting a single 512-dimensional embedding for visual embedding using the class token of ViT. The visual embedding is concatenated with the 64-dimensional encoding vector of start configuration and goal pose, resulting in a 576-dimensional environment embedding vector for the conditional noise prediction model.
Noise Prediction Network We adopt the CNN based architecture from [14] as the conditional noise prediction model, which is a 3-level UNet architecture consisting of conditional residual blocks with channel dimensions [256, 512, 1024]. The model encodes the time step into a latent vector of 256 dimensions through a multi-layer perceptron (MLP), which is concatenated with the environment embedding from the observation encoder, resulting an 831-dimensional conditional vector.
Loss Function The objective of the noise prediction network is to predict the noise added to the original trajectory.
Experiments
We conduct experiments both in simulation and on a physical Franka Panda robot to evaluate DiffusionSeeder. In the following sections, we denote DiffusionSeeder as DiffusionSeeder combined with cuRobo, unless otherwise specified.
Simulation We evaluate DiffusionSeeder on the MπNet simulation test set of 1791 problems. Each problem has a scene from the same scene types as the training data but with different configuration. We compare DiffusionSeeder to BiTStar, MπNet and cuRobo(v0.6.2).
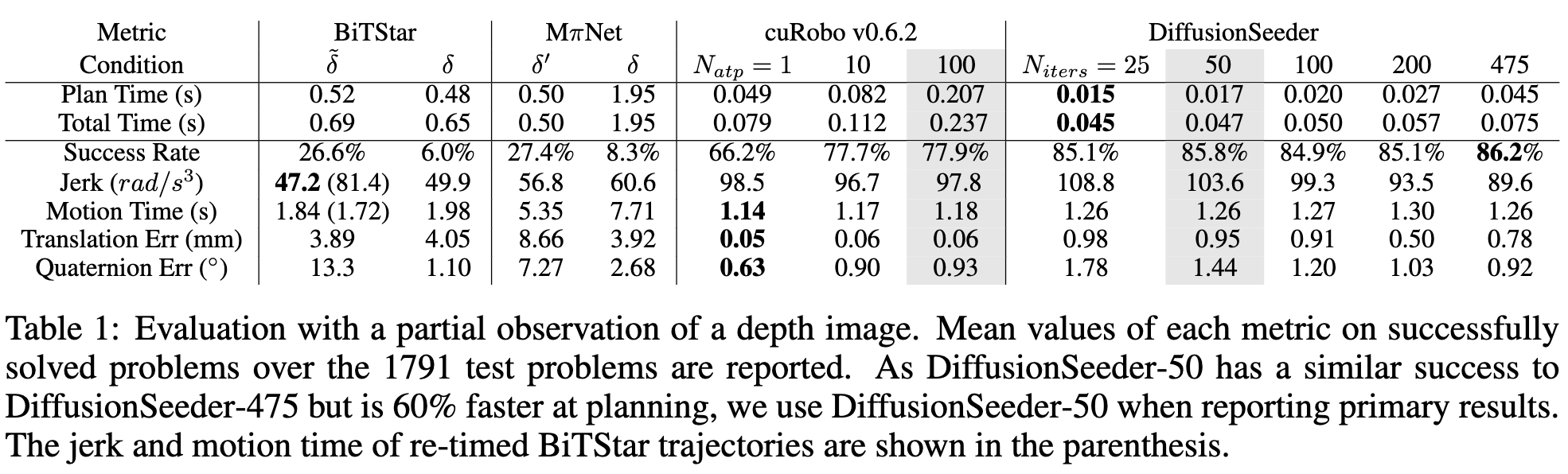
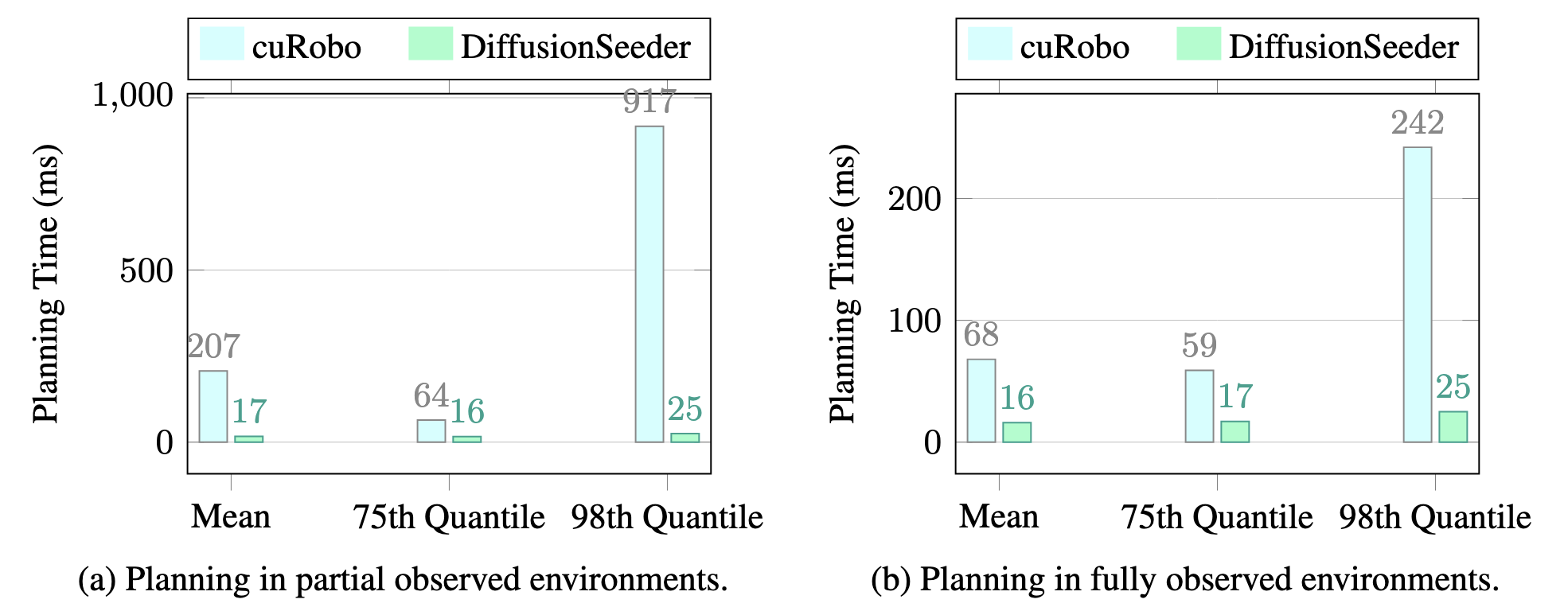
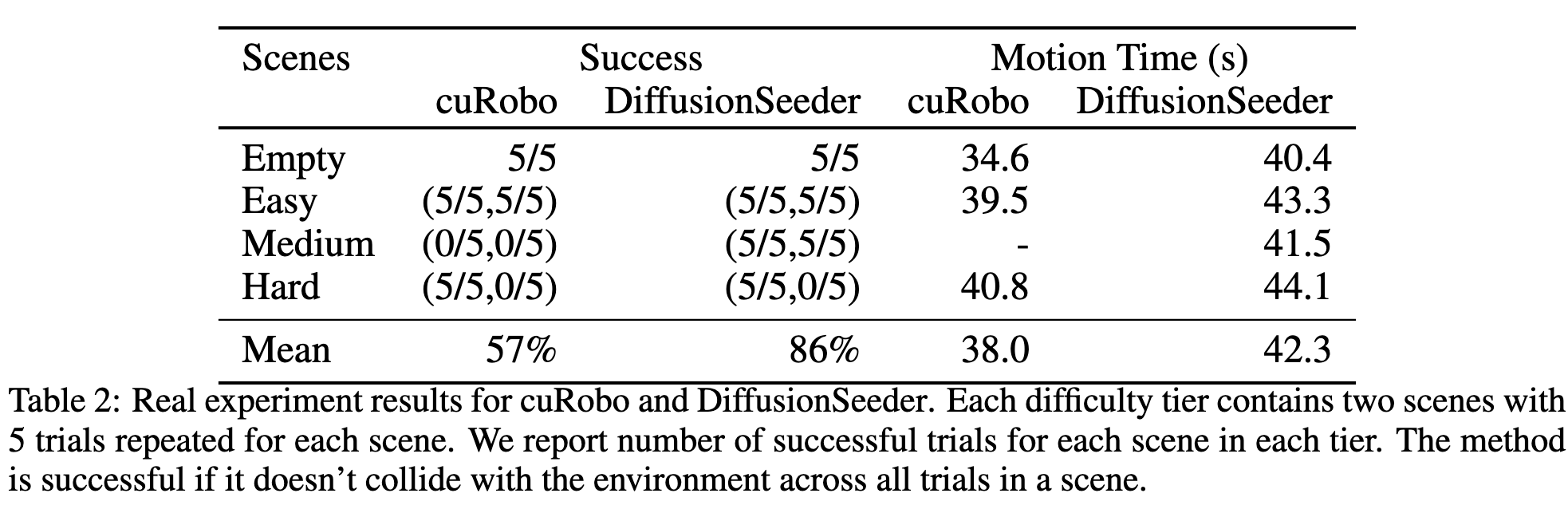
Physical We conduct experiments on a Franka Panda robot across 6 scenes, categorized into 3 difficulty tiers with 2 scenes from each tier and also an empty scene. None of the environment setups are part of our training dataset. In each scene, we select three poses that the robot needs to reach sequentially, repeating 5 times. A method is considered successful if it avoids collisions across all trials in a scene. In addition to success, we also report the time the robot was executing trajectories as Motion Time.
Citation
If you use this work or find it helpful, please consider citing our work.
@article{huangdiffusionseeder,
title={DiffusionSeeder: Seeding Motion Optimization with Diffusion for Rapid Motion Planning},
author={Huang, Huang and Sundaralingam, Balakumar and Mousavian, Arsalan and Murali, Adithyavairavan and Goldberg, Ken and Fox, Dieter},
booktitle={8th Annual Conference on Robot Learning},
year={2024}
}